
In this article you will find basic information about change data capture and high level view of the Kafka Connect. Then see how one of the connectors (Debezium PostgreSQL) can work in standalone mode (without the platform) - moving CDC to another level of simplicity.
But starting from the beginning.
If you somehow slept away last couple of years and missed Kafka / ‘Events being complementary to state’ revolution, the quick summary might be:
- things happen => it’s good to think about it as events => we have Kafka to handle this
- a lot of world’s description is still state based => many times it would be great if it was event based => and we have Kafka Connect to handle this.
When state is kept in databases then turning every db change to event naturally leads to CDC (Change Data Capture) techniques.
The idea is that in most dbs data is already, at some level, stored as events and the trick is to connect to this store.
In case of databases, this store is most likely
- some kind of a journal
like PostgreSQL’s WAL (Write-Ahead Log) where all the db operations are sequentially logged, and only after and based on this journal, changes are “materialized” in destination tables (a mechanism that provides recovery after crashes and reduces the number of disk writes) - Or - the other way around - some replication purpose mechanism
like Mongo’s Oplog (operations log) which stores all replica master’s changes so that the slaves can use them to sync.
Either way - we have a mean to be informed anytime the db state has changed.
Kafka & Kafka Connect Platform
To put this knowledge into practice we can use Kafka as a destination event log, and populate it by Kafka Connect reading db changes from either a journal or oplog as described above. This is easilly summarized by a diagram from Confluent page (the company behind Kafka)
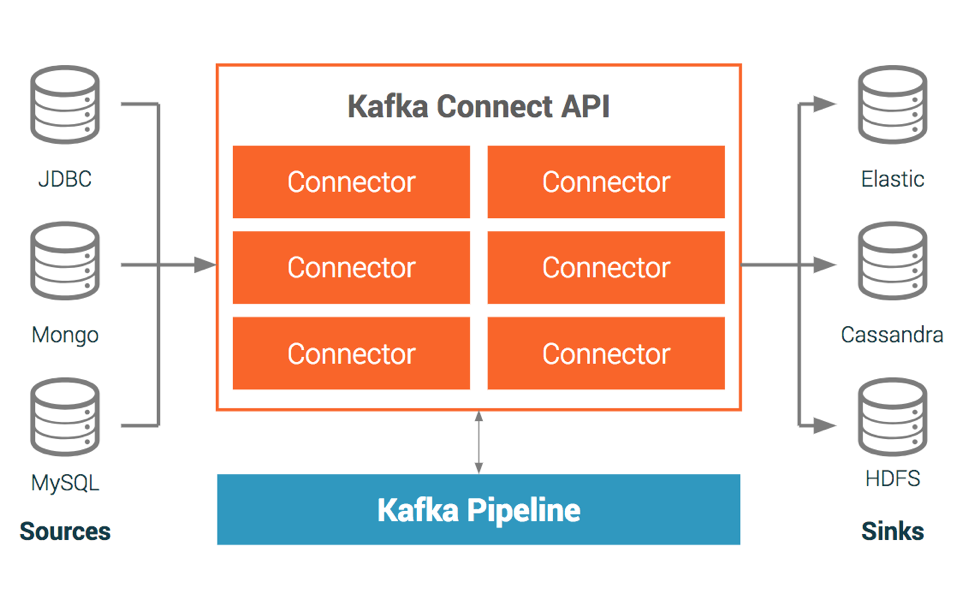
In my description I’ve purposely focused on reading the changes, as this where the magic happens (cdc).
Of course there is also the twin - writing side, which is just… writing.
The Kafka Connect Platform is build in a pluggable way, where Confluent provides the platform and API and everybody can provide connectors - that read / write data from different data sources (file, PostgreSQL, MongoDB, AWS S3, ActiveMq, etc…)
Among many - popular choice is Debezium - an open source project developed by Red Hat - providing connectors to MySql, PostgreSQL, SQL Server and MongoDB (and Oracle being incubated at the time of writing).
It all may look easy enough but in many cases isn’t.
Kafka Pipeline is Kafka and Zookeper and Kafka Connect is basically another Kafka cluster on steroids.
While installing all of them locally for dev purpose is super simple thanks to Docker images provided by Confluent
https://hub.docker.com/u/confluentinc
https://github.com/confluentinc/cp-docker-images
doing it in on prod might be tricky, especially in a cloud, and some devops maturity is expected.
Of course, as Jay Kreps wrote on Twitter - you don’t need to do it by yourself, when they (Confluent) offer Kafka as a service for a few cents per GB of writes.
The thing is - sometimes it’s just not your decision and in some organizations these decisions take time.
And sometimes you just need to prototype and play with CDC and the question is - can you do it without a platform and still use the abstraction provided by Kafka Connectors?
It appears you can.
CDC With no Platform
It turns out, that Debezium connectors (mentioned above) can work in embedded mode, which basically means that that you can add 2 dependencies and some configuration and your app will level up, gaining the CDC ability.
Let’s see it in action with small example using the Spring Boot.
To focus attention let’s assume that we have PostgreSQL table
orders (id, description)
and we want to react to all CRUD operations performed on it, like here:
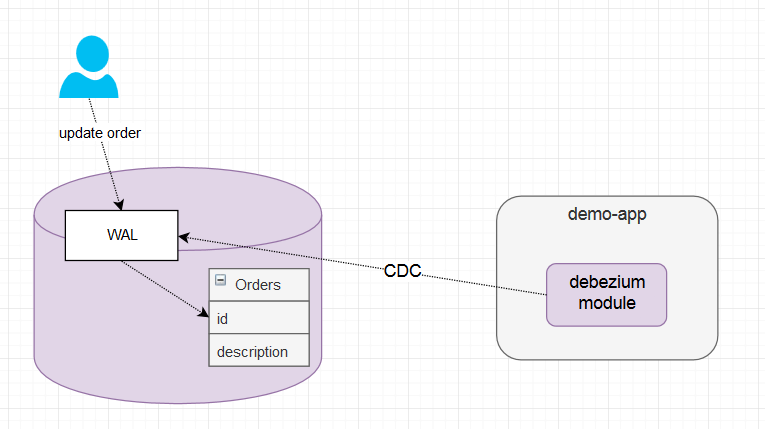
So everytime anyone performs any CRUD operation on orders table, it’s firstly reflected in WAL (by PostgreSQL inner workings). Inside the Demo App we have Debezium Connector monitoring WAL and notifying the app about every change.
The steps to make PostgreSql Debezium Connector working for our app would be
- add two dependencies
dependencies {
implementation("io.debezium:debezium-embedded:0.9.5.Final")
implementation("io.debezium:debezium-connector-postgres:0.9.5.Final")
}
Configuration debeziumConfiguration() {
return io.debezium.config.Configuration.create()
.with("connector.class", "io.debezium.connector.postgresql.PostgresConnector")
.with("offset.storage", "org.apache.kafka.connect.storage.MemoryOffsetBackingStore")
.with("offset.flush.interval.ms", 60000)
.with("name", "orders-postgres-connector")
.with("database.server.name", "orders")
.with("database.hostname", "localhost")
.with("database.port", 5432)
.with("database.user", "postgres")
.with("database.password", "postgres")
.with("database.dbname", "demo")
.with("table.whitelist", "public.orders")
// .with("snapshot.mode", "never")
.build();
}
Probably you can figure out most of the params by yourself, if not you can check here.
- With the above configuration configure and start the engine
EmbeddedEngine engine = EmbeddedEngine.create()
.using(debeziumConfiguration)
.notifying(this::handleEvent)
.build();
executor.execute(engine);
providing it with a reference to the handleEvent method that will be executed every time db change is captured.
- There - decide what operations react to, eg.
private void handleEvent(SourceRecord sourceRecord) {
Struct sourceRecordValue = (Struct) sourceRecord.value();
Operation operation = Operation.forCode((String) sourceRecordValue.get(OPERATION));
if (operation != Operation.CREATE) {
log.error("unknown operation");
return;
}
Struct after = (Struct) sourceRecordValue.get(AFTER);
changesCaptured.add(after);
}
The whole demo can be checked here,
where the mechansim is easilly tested with Spock Spec - DebeziumCDCDemo.groovy
which inserts new record to the orders table and checks wheter the OrdersWatch component reacted to the change.
Spec uses Testcontainers framework with PostgreSQL Docker Image so the demo is working by it’s own, and no external database setup is needed.
Few things to keep in mind
Enabling Replication is PostgreSQL
WAL - our journal of all operations, is not publically available by default.
PostgreSQL provides infrastructure to stream the modifications performed via SQL to external consumers by mechanism called logicaldecoding.
To make it work for us we need to provide some configuration and register proper plugin (both operations on PostgreSQL side).
I’m using Docker Image provided by Debezium which is already doing all of this for me, but one can easilly inspect the image or read “Setting up PostgreSQL” from Debzium page to do it by himself. This need to be done wheter you use the Platform or not.
Offset Tracking
Debezium Connector needs to keep track of what was the last change it read from WAL.
This is done by keeping offsets and in demo example we store it in the memory
.with(“offset.storage”, “org.apache.kafka.connect.storage.MemoryOffsetBackingStore”)
of course this is ok for tests but it will result in the connector reading WAL from the beginning everytime app is restarted.
You can also use
org.apache.kafka.connect.storage.FileOffsetBackingStore
but it may not work properly in cloud or for more than one instance of an app.
Then there is of course
org.apache.kafka.connect.storage.KafkaOffsetBackingStore
but we are trying to do it without platform.
If none of these stores work for you, you can easily implement your own BackingStore - tracking the offset e.g. in PostgreSQL itself. Basically it’s implementing two methods: get() and set() from OffsetBackingStore interface which read and save offset to the store of your choice.
Overusing might not be a good idea
This mechanism is powerful and while it may have it’s usages, it’s easy to overdose and you shouldn’t end up with every microservice reading each other db logs.
Don’t read the state, focus on business events, don’t couple yourself to models that don’t belong to your service. Basically read “Turning the database inside-out with Apache Samza” by Martin Kleppmann and “Designing Event-Driven Systems” by Ben Stopford :)
I believe it is safe enough to use it as a transition solution, like when extracting microservice from a bigger monolithic app. For other cases - proceed with caution.